Seq2seq(Sequence-to-Sequence)란?
Seq2seq(Sequence-to-Sequence)는 하나의 시퀀스(Sequence)를 입력받아 다른 시퀀스를 출력하는 딥러닝 모델 구조입니다. 특히, 인코더(Encoder)와 디코더(Decoder)라는 두 가지 핵심 구성 요소로 이루어져 입력과 출력의 길이가 달라도 된다는 특징을 가집니다. 이는 기계 번역, 챗봇, 텍스트 요약 등 다양한 자연어 처리(NLP) 문제에 혁신을 가져온 매우 중요한 모델입니다.
Seq2seq의 기본 구조 : 인코더-디코더
Seq2seq 모델은 입력 시퀀스를 내부적으로 이해하고(인코딩),
이를 바탕으로 새로운 출력 시퀀스를 생성하는(디코딩) 과정을 수행합니다.
1 📥 인코딩 (Encoding) | NLU, EOS 토큰, Non-Auto-Regressive
입력 시퀀스(예: 원문 문장)의 모든 정보를 순차적으로 처리하여
하나의 고정된 크기의 컨텍스트 벡터(Context Vector)로 압축합니다.
이 벡터는 입력 시퀀스의 핵심 의미를 담고 있습니다.
작동 방식
- RNN 계열(주로 LSTM이나 GRU) 네트워크를 사용하여 입력 단어들을 순서대로 처리합니다.
- 각 단어를 처리할 때마다 내부의 은닉 상태(Hidden State)가 업데이트되며,
이전 단어들의 정보가 누적됩니다. - 문장의 마지막을 알리는 <EOS> 토큰을 통해 입력의 끝을 인지하고 정보 압축을 완료합니다.
- 최종 은닉 상태가 문장 전체의 의미를 담은 컨텍스트 벡터가 됩니다.
⬇
2 컨텍스트 벡터 (Context Vector)
인코더에 의해 생성된 벡터로, 입력 시퀀스 전체의 정보를 요약하고 압축한 '생각' 또는 '의미'를 표현합니다.
이 벡터는 디코더로 전달되어 출력 시퀀스 생성의 기반이 됩니다.
⬇
3 📤 디코딩 (Decoding) | NLG, BOS 토큰, EOS 토큰, Auto-regressive
인코더로부터 전달받은 컨텍스트 벡터를 바탕으로,
목표 언어의 단어들을 하나씩 순차적으로 생성하여 새로운 출력 시퀀스(예: 번역된 문장)를 만듭니다.
작동 방식
- 인코더의 컨텍스트 벡터를 디코더 RNN의 초기 상태로 설정합니다.
- 문장 시작을 알리는 <BOS> 토큰을 첫 입력으로 받아 첫 단어를 예측합니다.
- 이전 예측 단어를 다음 입력으로 사용하는 자기회귀(Auto-regressive) 방식으로
단어를 순차적으로 생성합니다. - <EOS> 토큰이 나올 때까지 단어 생성을 반복하여 출력 시퀀스를 완성합니다.
이처럼 Seq2seq는 인코더-디코더 구조를 통해 시퀀스 변환을 수행하며,
이 구조는 자연어 처리의 핵심 과제인 NLU와 NLG가 결합된 형태입니다.
인코더 & 디코더 심층 분석
1. 인코더(Encoder) : 문장의 의미를 압축하는 NLU
인코더는 입력 문장의 모든 단어를 순차적으로 처리하여 문맥 정보를 하나의 벡터에 응축시키는 역할을 합니다.
작동 방식
RNN(주로 LSTM, GRU)이 입력 문장의 단어 임베딩 벡터를 처음부터 끝까지 순서대로 읽습니다.
각 단어를 처리할 때마다 내부의 은닉 상태(Hidden State)가 업데이트되며, 이전 단어들의 정보가 누적됩니다.
특수 토큰의 역할
<EOS> (End Of Sequence) : 필수
: 문장의 마지막을 알리는 <EOS> 토큰은 매우 중요합니다. 인코더는 이 토큰을 만나야 입력이 끝났음을 인지하고, 그때까지 누적된 정보를 담은 최종 은닉 상태를 컨텍스트 벡터로 확정합니다.
<BOS> (Beginning Of Sequence) : 불필요
: 반면, 문장의 시작을 알리는 <BOS> 토큰은 인코더에서 일반적으로 사용되지 않습니다. 인코더는 구조상 자연스럽게 시퀀스의 첫 번째 단어부터 정보를 읽기 시작하므로, 시작을 명시하는 별도의 토큰이 필요하지 않습니다.
양방향성 (Bidirectionality)
더 높은 성능을 위해 인코더는 주로 양방향 RNN (Bi-RNN, Bi-LSTM 등)으로 구현됩니다.
이는 문장을 정방향(왼쪽→오른쪽)과 역방향(오른쪽→왼쪽)으로 모두 읽어 각 단어의 앞뒤 문맥을 모두 반영하기 위함입니다. 이를 통해 훨씬 더 풍부하고 정확한 컨텍스트 벡터를 생성할 수 있습니다.
2. 디코더(Decoder) : 조건부로 문장을 생성하는 NLG
디코더는 인코더로부터 컨텍스트 벡터를 받아, 이를 바탕으로 출력 문장을 생성합니다.
자기회귀 (Auto-regressive)
디코더의 가장 큰 특징은 '자기회귀' 방식입니다.
즉, 이전에 자신이 생성한 단어를 다음 단어를 생성할 때의 입력으로 사용합니다.
- 생성을 시작하기 위해 문장의 시작을 알리는 <BOS> 토큰을 첫 입력으로 받습니다.
- 컨텍스트 벡터와 <BOS> 토큰을 이용해 첫 번째 단어를 예측합니다.
- 예측된 단어를 다음 입력으로 사용하여 두 번째 단어를 예측합니다.
- 이 과정을 반복하다가, 문장의 끝을 의미하는 <EOS> 토큰이 생성되면 작동을 멈춥니다.
Teacher Forcing (교사 강요)
모델을 훈련시킬 때는 자기회귀 방식의 불안정성을 보완하기 위해 '교사 강요' 기법을 사용합니다. 이는 모델이 이전에 예측한 단어가 틀렸더라도, 다음 입력으로는 정답 단어를 알려주어 학습을 더 빠르고 안정적으로 진행시키는 방법입니다.
작동 원리의 핵심 : 조건부 언어 모델
(Conditional Language Model)
Seq2seq는 조건부 언어 모델(Conditional Language Model)이라고도 불립니다.
인코더가 만든 컨텍스트 벡터가 바로 이 '조건'의 역할을 하는 것입니다.
이 때문에 Conditional Text Generation, Text2Text Generation이라는 명칭으로도 불립니다.
일반 언어 모델 (Language Model)
"나는 어제 저녁에 맛있는 떡볶이를..."이라는 문장이 있다고 상상해 보세요.
일반 언어 모델은 이 다음에 올 가장 자연스러운 단어를 예측합니다. '먹었다' 라든지 '만들었다' 같은 단어들이겠죠?
이 모델은 오직 앞에 나왔던 단어들의 흐름만 보고 다음 단어를 예측해요.
즉, "이전 단어들이 주어졌을 때, 다음 단어가 나올 확률은 얼마일까?"만 계산하는 거죠.
마치 소설의 다음 문장을 쓰듯이, 다른 어떤 특별한 정보(조건) 없이 순수하게 언어의 패턴만을 따릅니다.
조건부 언어 모델 (Seq2seq)
이번에는 좀 다릅니다. 제가 친구에게 "오늘 점심 메뉴 추천해줘"라고 물었다고 해볼게요.
그러면 저는 단순히 다음에 올 단어를 예측하는 게 아니라,
질문("오늘 점심 메뉴 추천해줘")의 '조건'에 맞춰서 대답을 할 거예요. Seq2seq는 바로 이런 방식입니다.
입력 문장 X (질문)라는 추가 정보가 주어졌을 때, 이 입력 문장 X를 모두 고려하여 다음 단어가 나올 확률을 계산합니다.
즉, 그냥 다음 단어를 예측하는 것을 넘어, 주어진 '조건'에 딱 맞는 응답이나 번역을 생성할 수 있게 됩니다.
여기서 인코더가 만든 '컨텍스트 벡터'가 바로 이 중요한 '조건'의 역할을 하는 셈이죠.
이것이 바로 Seq2seq가 단순한 텍스트 생성이 아닌, 입력에 맞는 '번역'이나 '응답'을 생성할 수 있는 이유입니다.
Seq2seq의 한계와 어텐션(Attention)
기본적인 Seq2seq 모델은 한 가지 명확한 한계를 가집니다.
바로 인코더가 문장의 모든 정보를 하나의 고정된 크기의 컨텍스트 벡터에 억지로 구겨 넣어야 한다는 점입니다.
❗ 정보 병목 현상 (Information Bottleneck)
입력 문장이 길어질수록, 초반부의 중요한 정보들이 컨텍스트 벡터에 제대로 담기지 못하고 소실되는 문제가 발생합니다. 마치 긴 이야기를 듣고 앞부분을 잊어버리는 것과 같습니다.
이 문제를 해결하기 위해 어텐션(Attention) 메커니즘이 등장했습니다.
어텐션(Attention) 메커니즘의 이해
어텐션 메커니즘은 디코더가 출력 단어를 생성할 때, 입력 시퀀스의 특정 부분에 선택적으로 집중할 수 있도록 하는 기술입니다. 이는 기존 Seq2seq 모델의 정보 병목 현상을 해결하고, 장거리 의존성 문제를 완화하여 번역 및 생성 성능을 비약적으로 향상시켰습니다.
핵심 아이디어
어텐션은 디코더가 각 단어를 생성할 때마다,
인코더가 만들었던 입력 문장의 모든 은닉 상태(Hidden States)를 다시 참고하는 기술입니다.
작동 방식
- 유사도(Alignment Score) 계산
: 디코더의 현재 시점 은닉 상태(st)와 인코더의 각 시점 은닉 상태(hi)를 비교하여,
두 벡터 간의 유사도(예: 내적)를 계산합니다. 이 점수는 현재 출력에 특정 입력 단어가 얼마나 관련이 있는지 나타냅니다. - 가중치(Attention Weight) 할당
: 계산된 유사도 점수들을 Softmax 함수에 통과시켜 각 입력 단어에 대한 '가중치'(αti)를 할당합니다.
이 가중치의 합은 1이 되며, 현재 출력 단어를 생성할 때 어떤 입력 단어에 더 집중해야 하는지를 확률적으로 나타냅니다. - 컨텍스트 벡터(ct) 생성
: 인코더의 각 은닉 상태(hi)에 해당 가중치(αti)를 곱한 후 모두 합산하여
새로운 '컨텍스트 벡터'(ct = Σ αtihi)를 생성합니다.
이 컨텍스트 벡터는 현재 출력 시점에 가장 중요한 입력 정보들을 가중합한 결과입니다. - 디코더의 출력 예측
: 디코더는 이 새로운 컨텍스트 벡터(ct)와 자신의 현재 은닉 상태(st)를 결합하여 다음 출력 단어를 예측합니다. 이렇게 매 시점마다 관련 입력 정보에 '집중'하여 활용함으로써, 긴 문장에서도 정보 손실 없이 훨씬 더 정확하고 문맥에 맞는 결과물을 만들어낼 수 있습니다.
활용 분야 : NLG Task
Seq2seq 모델은 주로 다음과 같은 자연어 생성(NLG) 태스크에서 핵심적으로 활용됩니다.
1 기계 번역
"나는 학생입니다" ➡️ "I am a student"
2 챗봇
[날씨 질문] ➡️ "오늘 서울의 날씨는 맑습니다."
3 텍스트 요약
[긴 뉴스 기사] ➡️ [핵심 내용 3줄 요약]
4 음성 인식
[음성 파형 데이터] ➡️ "안녕하세요"
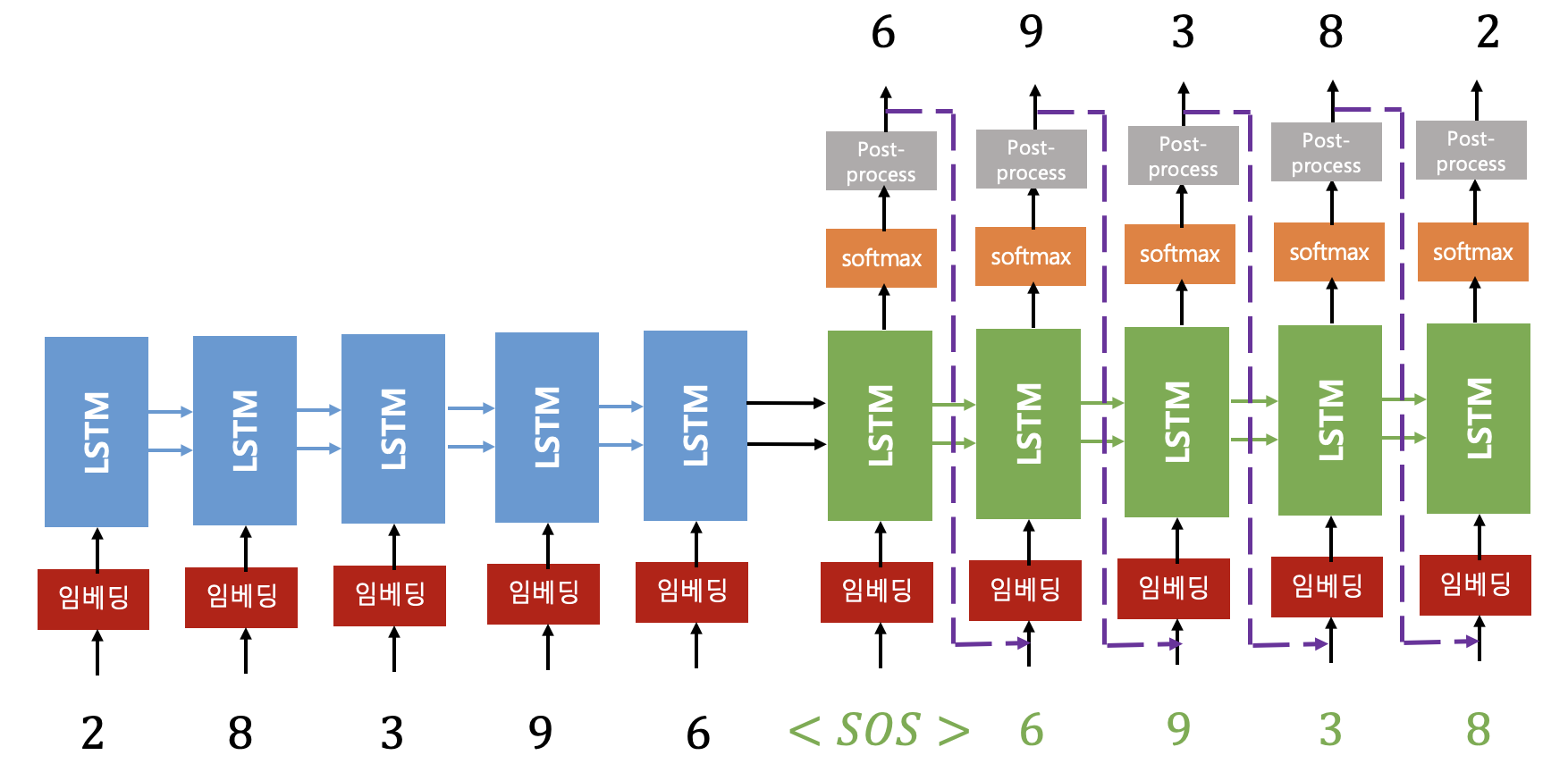
Seq2seq 자세한 전체 과정
다음은 입력 시퀀스가 최종 출력 시퀀스로 변환되는 Seq2seq 모델의 전체적인 흐름입니다.
1인코더 (Encoder) : 문장을 읽고 의미를 압축하는 단계
인코더의 목표는 입력 문장의 모든 정보를 담은 단 하나의 컨텍스트 벡터(Context Vector)로 압축하는 것입니다.
1. 텍스트 준비 (Text Preprocessing)
1️⃣ 토큰화
입력 문장을 의미 있는 최소 단위인 단어(토큰)로 분리합니다.
"I am a student" ➡️ ['I', 'am', 'a', 'student']
2️⃣ 특수 토큰 추가
문장의 시작과 끝을 나타내는 <SOS> (Start Of Sequence), <EOS> (End Of Sequence)
토큰을 추가합니다. 인코더에서는 주로 `<EOS>`만 사용됩니다.
['I', 'am', 'a', 'student', '<EOS>']
3️⃣ 정수 인코딩
각 단어를 고유한 숫자(정수) ID로 매핑합니다. 이는 단어 사전을 기반으로 합니다.
['I', 'am', 'a', 'student', '<EOS>'] ➡️ [5, 12, 8, 3, 1] (예시)
2. 임베딩 (Embedding)
각 정수 ID를 미리 학습된 고차원의 실수 벡터(임베딩 벡터)로 변환합니다.
이 벡터들은 단어의 의미적, 문법적 정보를 포함합니다.
[5, 12, 8, 3, 1] ➡️ [ [0.9, 0.2, ...], [0.1, 0.4, ...], ... ] (벡터 시퀀스)
이제 입력 문장은 컴퓨터가 연산할 수 있는 벡터들의 시퀀스(행렬)가 됩니다.
3. RNN 계층 처리 및 컨텍스트 벡터 생성
인코더의 RNN(주로 LSTM 또는 GRU, 종종 양방향)이
임베딩 벡터 시퀀스를 순서대로 하나씩 입력받아 처리합니다.
각 시점의 RNN 셀은 현재 단어 벡터와 이전 시점의 은닉 상태를 받아 새로운 은닉 상태를 계산합니다.
이 과정에서 문맥 정보가 은닉 상태에 점진적으로 누적됩니다.
최종 `<EOS>` 토큰까지 처리한 후의 최종 은닉 상태가 바로
전체 입력 문장의 의미를 압축한 컨텍스트 벡터가 됩니다.
[Emb('I'), Emb('am'), ..., Emb('<EOS>')]
➡️ RNN Cells ➡️ Final Hidden State = Context Vector
2디코더 (Decoder) : 의미를 바탕으로 새 문장을 생성하는 단계
디코더는 인코더가 생성한 컨텍스트 벡터를 바탕으로 출력 문장을 한 단어씩 순차적으로 생성합니다.
1. 초기화
디코더 RNN의 첫 번째 은닉 상태는 인코더의 최종 결과물인 컨텍스트 벡터로 설정됩니다.
이는 인코더가 이해한 전체 입력 문장의 의미를 디코더에게 전달하는 역할을 합니다.
2. 첫 단어 생성
디코더의 초기 입력으로 문장의 시작을 알리는 `<BOS>` 토큰의 임베딩 벡터가 들어갑니다.
디코더 RNN 셀은 `<BOS>` 토큰 벡터와 컨텍스트 벡터(초기 은닉 상태)를 처리하여 출력 벡터를 생성합니다.
Softmax 적용
이 출력 벡터는 Softmax 함수를 통과하여
목표 언어의 단어 사전에 있는 모든 단어에 대한 확률 분포로 변환됩니다.
Output Vector ➡️ Softmax ➡️ { "나는": 0.92, "너는": 0.01, ... } (확률 분포)
단어 선택
가장 확률이 높은 단어 (예: "나는")가 첫 번째 출력 단어로 선택됩니다.
3. 다음 단어 생성 (자기회귀, Autoregressive)
핵심 원리
방금 생성된 단어 (예: "나는")의 임베딩 벡터가 다음 시점 디코더 RNN 셀의 입력으로 사용됩니다. 이는 디코더가 이전에 생성한 단어를 기반으로 다음 단어를 예측하는 자기회귀(Autoregressive) 방식을 따릅니다.
Previous Output: "나는"
➡️ Emb("나는") + Previous Hidden State ➡️ Next RNN Cell
RNN 셀은 새로운 입력 벡터와 이전 은닉 상태를 받아 다시 새로운 출력 벡터를 만들고,
Softmax를 통해 다음 단어의 확률을 계산합니다. 이 과정이 반복됩니다.
4. 종료 조건
디코더가 출력 단어를 생성하는 과정은 `<EOS>` (End Of Sequence) 토큰이 예측될 때 종료됩니다.
이로써 하나의 완전한 출력 시퀀스가 완성됩니다.
... ➡️ "학생입니다" ➡️ "<EOS>" ➡️ Generation Ends
이처럼 임베딩은 단어를 기계가 이해하는 벡터로 바꾸는 과정이며, Softmax는 모델의 숫자 출력을 우리가 아는 단어에 대한 확률로 바꿔주는 필수적인 과정입니다. 또한, 디코더가 자신의 이전 출력값을 다음 입력으로 계속 사용하는 자기회귀 방식(Autoregressive)이 Seq2seq 모델의 핵심적인 작동 원리입니다.